Quantization
How to think about quantization for inference? The quantization that we do for inference is called as Post training quantization (PTQ).
Broadly, there are two types of quantization for inference
- Weight only quantization
- Weight + activation quantization
The objective of quantization during inference is to make the model size smaller and make inference faster. The objective of this blog is to clearly understand the different kind of quantizations and the overall landscape.
Weight only quantization
This is sometimes called as static quantization, where only the weights are targetted. After the process, we get a model with weights in lower precision. These lower precision weights help relieve pressure on memory bandwidth during inference, especially during decode phase which is memory bound (in case of small batch sizes). The GPU has to do less work while moving the model weights for decoding, which results in faster inference (tokens/s). Lower precision weights also help in making more space for KV cache, hence, its better for long context decoding too. Weight only quantization is a offline process, where we run the process once and get the weights in lower precision plus the scales for these weights which are used during inference to upcast them back to higher bandwidth.
Weight only quantization can be done with or without calibration dataset. If it is done without calibration dataset, the weights are quantized to lower precision. If we do this kind of naive quantization (round to nearest), the accuracy degradation is high. If we have access to a calibration dataset, we can use it to quantize the weights (eg: GPTQ). It helps in preserving the accuracy of the model.
Calibration dataset typically includes the prompts of similar kind to what the model is expected to see during production deployment.
In case of weight quantization with or without calibration dataset, if we just keep small percentage of the outlier weights in higher precision, the accuracy degradation is much lesser. But the problem arises, how do we select those small percentage weights that we do not quantize? There are a few ways we can select the weights that we should leave out of quantization
- Randomly select the channels (a few values across hidden dimension) and leave them out from the quantization process
- Select the weights which have a very high value (weight magnitude). This is similar to what bitsandbytes quantization does
- Select the weights which produce the highest activation values. These are activation aware quantization methods eg: AWQ1
During inference, the model loads lower precision weights (eg: INT8) and applies the scale factor to upcast them to higher precision (eg: BF16) and perform GEMMs in that higher precision. The higher precision weights are never actually materialized to HBM.
Different frameworks have different implementations of loading and doing computation for weight only quantization. This blog compares the performance in terms of throughput between vLLM and TensorRT.
A note of where weight only quantization will not help - If the model is operating in the compute bound region (eg: during pre fill, high batch size), weight quantization does not help much. The model loads the weights only once and does large number of computations. For these computations, the kernel needs to de-quantize the model weights which are quantized. This step adds a computational overhead which is sometimes more than the improvements we get from the memory bandwidth savings.
Weight + activation quantization
We can also choose to quantize the activations. Activation quantization allows us to use lower precision math and faster tensor cores. Since the weights are already in lower precision, if the activations somehow are also in lower precision, we can directly use lower precision tensor cores, which are typically much faster than typical BF16 tensor cores. For example, INT8, Float8, INT4 tensor cores are 4x, 2x and 8x faster than BF16 tensor cores in NVIDIA 4090 GPU.
But performing activation quantization is slightly more involved than weight only quantization:
- Calibration dataset requirement is mandatory for weight + activation quantization. Activations are dynamic and change for every prompt. To select an appropriate scales for later online serving, the calibration dataset is run through the model and the activation ranges are captured. These are then saved with the model weights as a separate key in the model state dice (scales).
- During inference, along with the weight+weight scales, we load the activation scales and quantize the activation to lower precision on the fly using these scales.
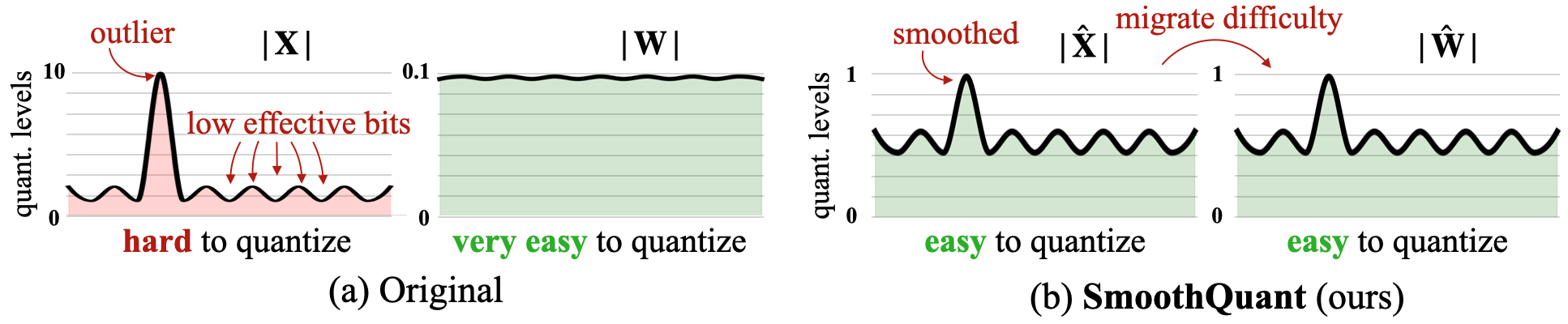
One of the popular techniques to achieve weight+activation quantization is SmoothQuant2. Activations can have very high outliers. If, weights are relatively smoother and smaller values, we can find a common factor by which we can multiply the weights and divide the activations. This way, the weights will not grow by much (because they were small to start with), but values of activations will go down a lot. After this, we can quantize both the weights and activations.
$Y = xW$ is same as $Y = (0.1x)(10W)$
Implementations
From an implementation perspective for these quantization schemes, here are a few important things to keep in mind
- Quantization Schemes: Schemes are the mathematical ways of quantizing a model. eg: AWQ, GPTQ
- Quantization Kernels: Kernels are implementations of schemes in different settings (batched load, non batched load etc.). eg: ExLlama v2, Marlin
The schemes also release their official kernels where they implement their own kernels. However, over time, others figure out ways to improve the computation and weight loading. For example, Marlin kernels are efficient implementations for FP16xInt4 which are used in 4 bit weight only quantization and can be applied for both GPTQ or AWQ.
Going deep in these schemes and kernels will make one realize that choosing the right quantization scheme is extremely nuanced. Ideally, to compare performance, we should look at (kernel x batch size x scheme x workload) comparisons.
Framework implementation of performing inference with a weight (and weights+activations) quantized model leads to different performance in terms of throughput. Refer to these two blogs on the performance comparison between vLLM and TensorRT.
If the model is operating in the compute bound region (eg: during pre fill, high batch size), weight quantization does not help much. The model loads the weights only once and does large number of computations. For these computations, the kernel needs to de quantize the model weights which are quantized. This step adds a computational overhead.
Performance examples
TBA