Mechanics of FP8 for LLMs
I am writing this to understand the role of FP8 data type in Systems for LLM. To follow along, you should have a basic understanding of transformer architectures, memory-bound vs compute-bound workloads, and GPU architecture fundamentals.
TLDR:
- In large-scale LLM training, FP8 reduces math precision without hurting stability by keeping accumulation + critical ops in BF16/FP32.
- Training is compute-bound: FP8 ≈ 1.3×–1.5× throughput gain with negligible convergence impact using blockwise scaling.
- Inference is memory-bound: benefit mainly footprint + bandwidth (~50% reduction in weights/KV cache, latency also sees some wins).
- There is no “standard” recipe to do FP8 training.
FP8 in deep learning
There are already good references1 to get a quick overview of the FP8 data type. Essentially, FP8 data type stores data in 8 bits, cutting down the memory requirement by 2x in comparison to BFloat16 (BF16), which is currently the most popular data type in which LLMs are trained and served. FP8 data type comes in different formats, E4M3 (higher precision, lower range) and E5M2 (lower precision, higher range), which serve different use cases. The details of the data type are mentioned in the FP8 formats for deep learning paper2.
With newer GPU architectures, the FP8 data type is getting native support in hardware eg, FP8 support in NVIDIA Hopper GPUs and micro-scaled FP data formats support in Nvidia Blackwell GPUs. It is now becoming viable to use it for both training and inference. Here’s an overview of different techniques where the FP8 data type can be used for different deep learning workloads, training, and inference.
graph LR
A[FP8] --> B[Training]
A --> C[Inference]
B --> H["Mixed precision FP8 training (more common)"]
B --> E[Quantization aware training, QAT]
C --> D[Static Post training quantization]
C --> G[Dynamic Post training quantization]
G --> F[Serving]
D --> F
FP8 for training and inference
Since the launch of Hopper GPUs, the FP8 has been natively supported in tensor core operations. This enables support of loading and performing FP8 math directly in tensor cores. The TFLOPS that H100 offers for FP8 is twice that of BF16 operations (3.9 TFLOPS vs 1.9 TFLOPS) 3. This helps in two ways:
- Matrix multiplication operations (or GEMM kernels) in transformer networks are 2x faster when done in FP8 instead of BF16
- Since the data type consumes less memory, the memory transfers are 2x faster (from HBM to cache, or over the network)
While both of these advantages help, FP8 plays a different role in training and inference. In general, training workloads are compute-bound (driven by large batch sizes), whereas inference workloads are memory-bound (especially during the decoding phase).
During training, using FP8 Tensor Cores can significantly reduce overall time since GEMM operations dominate the compute cost. During inference, if the model’s weights are stored in FP8 data type, the throughput will increase (especially during the decode stage) since the GPU will have to move half the amount of data.
Notice that for inferencing, to realize substantial benefits from the FP8 data type, we need a model whose weights are already in FP8. Running FP8 GEMMs on BF16 weights may not give noticeable speedups during inference because the decoding stage is memory-bound. There is no such strict requirement for training. During the training workload, we can (and often do) start with a higher precision data type (eg, BF16) and use FP8 in certain operations.
One would assume to get a 2x speed improvement across the board. However, reality is not that simple. The next few sections explain why.
FP8 training
In the training workload, we can think of using lower bit data type in two scenarios
- Native FP8 training
- Quantization aware training (QAT)
But before we discuss the training flow, we need to understand how the higher precision values are quantized to lower precision.
Quantizing to FP8
Quantization converts a BF16 tensor to FP8 by scaling its values so that they fit within the representable FP8 range. Consider a tensor $X$ in BF16 data type:
- Calculate the scale factor, $s = \frac{\max |X|}{\beta_{\mathrm{FP8}}}$, where $\beta_{\mathrm{FP8}}$ is the maximum magnitude that FP8 can represent
- Scale the tensor (still in BF16), $Y = \frac{X}{s}$
- Finally, convert to FP8 tensor, $\widehat{X} = \mathrm{clip}(\mathrm{round}_{\mathrm{FP8}}(Y))$, where we first round the scaled tensor $Y$ and then clip the resultant in the representable range of FP8
Practically in neural networks, we have to first decide our encoding strategy. How should we compute the scale factor? There are two ways:
- Current (or online) scaling: Calculate the scale factor for every tensor every time it is quantized. This incurs a significant overhead since it is a necessary step to be done before we run the actual matrix multiplication
- Delayed scaling: Instead, we can store the history of max values of the tensor in a buffer (amax history) and use the running average as the scale factor. In delayed scaling, the FP8 operator uses a scaling factor as well as emits a new scaling factor that is used to update the amax history. Both of these can happen asynchronously and hence incurs a lesser overhead than online scaling
Second, we have to decide, what values to use for the scale:
- Per tensor: Use the complete tensor to calculate the scale factor. A single tensor has a single scale factor associated with it
- Column-wise or row wise: Calculate a single scaling factor per column (or row). A single tensor has multiple scaling factors associated with it and separately stored. This is slower than per tensor scaling but results in better numerical stability. For example, for a MxK tensor, with column wise scaling, we would have K scales calculated and stored in FP32
- Block wise: Calculate a single scaling factor for different blocks of the tensor. This can be two dimension (eg: 128x128) or one dimensional (eg: 1x128). For example, for a 512x512 tensor, with (128x128) block scaling, we would have a 4x4 scaling tensor stored in FP32. Column wise (or row wise) scaling is a special case of block wise scaling where one dimension is equal to the number of columns (or rows)
Both of the above decisions are orthogonal and can be mixed into a recipe. For example, using delayed scaling with block wise scales or using online scaling with per tensor scales. With the release of blackwell GPUs, NVIDIA released support for microscaling format (MX), i.e MXFP8, MXFP4, MXFP6, and MXINT8. MX formats are a special case of block wise scaling where the scales are calculated for a block of 1x32 and stored in FP8 (E8M0 format). Blackwell GPUs support MXFP8 data types natively, which means, they compute the scales inside the GEMM path which is much faster than calculating the scale factor manually in software. A similar setup can be emulated on Hopper GPUs as well, but must be handled in the software stack by the user which adds a significant overhead.
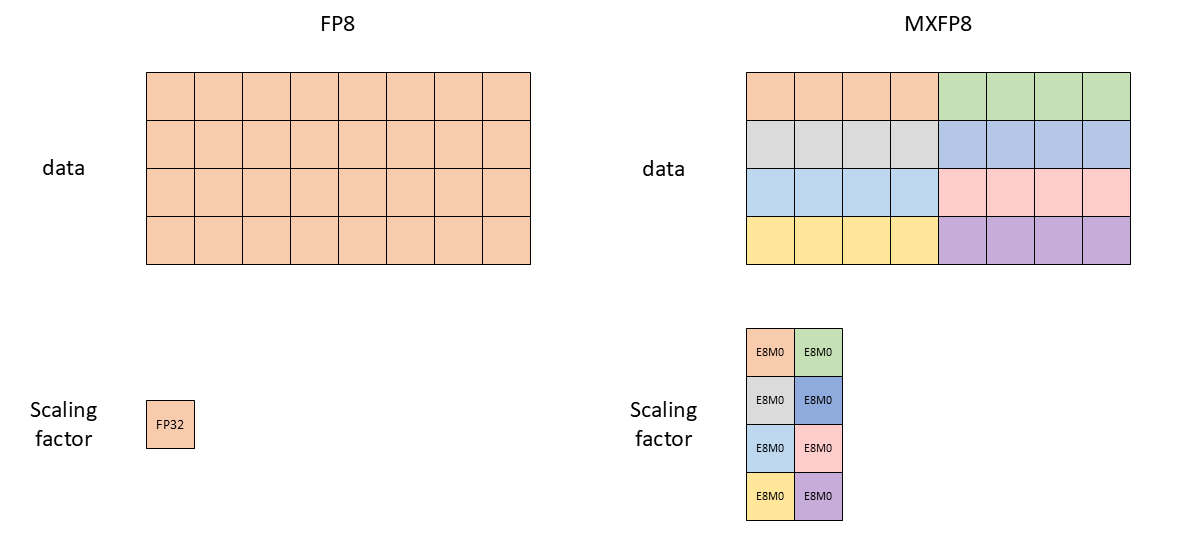
Figure: (Left) Per tensor scaling vs (Right) MXFP8 scaling. 1
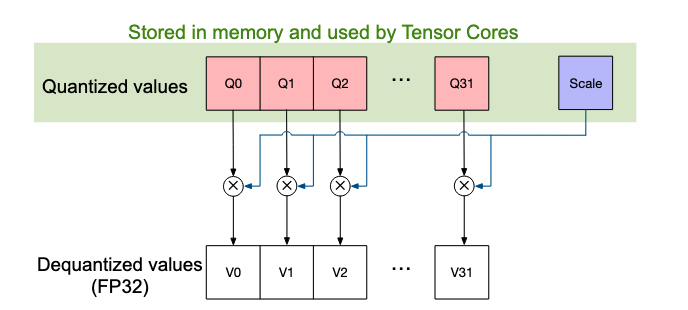
Figure: A single block of MXFP8 with 32 values and a single scale factor stored with them
For a deep dive into different quantization schemes, refer to the visual guide to quantization.
Native FP8 training
When I first started reading about the FP8 data type during training, my initial naive thought was that we could just initialize the weights in the FP8 data type and start the training, where all the model parameters, like weights, activations, gradients, and optimization states, could use the FP8 data type.
However, since the range of FP8 is so small, it is not suitable to represent extremely large or small values without rounding to inf or 0. For example, in E4M3 format of FP8, the smallest positive value that it can store is ~0.0019 4. Any tensor value smaller than this gets rounded to 0. This is problematic given that gradients can be very small, and optimizer states also need to store very small values. Even if we take a pretrained model that has its weights stored in BF16 and convert it to FP8 naively, a lot of the weights can become 0. This also means that if model parameters were updated directly in FP8, many small updates could be lost due to rounding to 0.
In practice, the optimizer states (usually) are stored in higher precision data types like BF16 or FP32. The weights are also maintained in higher precision like BF16 called the master weights. The forward pass quantizes the master weights to FP8 on the fly. After the backward pass, the optimizer updates the master weights, which are then quantized to FP8 for the next forward pass. The quantization process comes with an overhead. This overhead dominates runtime at smaller matrix sizes but as the matrix sizes increase, the overhead is tiny in comparison to the actual matmul operation5.
Coming back to training, during the forward pass the activations ($X$) and weight matrix ($W$) are quantized to FP8. After that, both matrices are multiplied using tensor cores (handled by GEMM kernels). The accumulation of the output happens in a higher precision (either BF16 or FP32). The final result requires multiplying the output of GEMM by the scale factors of the input. This means we need to store the scale factors separately.
flowchart TD
%% Inputs and master weights
XA[Layer n activations X, BF16] -->|quantize: divide by s_X, round and clip to FP8| Xhat[X̂ FP8 with scale s_X]
Wmaster[Layer n master weights W, BF16] -->|quantize each forward: divide by s_W, round and clip to FP8| What[Ŵ FP8 with scale s_W]
Xhat --> GEMM
What --> GEMM
GEMM[FP8 by FP8 Tensor Cores<br/>Fused rescale by s_X*s_W<br/>Accumulate to BF16] --> Zbf16[Matmul output, BF16]
Zbf16 -->|bias, residual, layer norm, activation BF16| Aout[Layer n+1 activations X, BF16]
Instead of offloading all the operations to FP8, typically only matrix multiplications that dominate the training time, are offloaded to FP8. This is because, other operations are very sensitive to the lower range and precision of FP8 and can lead to very high accuracy degradation if done in FP8.
Overall, there are a lot of interesting design choices 6 that can be made during training:
- The weights can be either replicated and stored as master weights in BF16, or quantized and stored to FP8 throughout the training run
- The gradients for the backward pass can either be kept in BF16 and quantized to FP8 on the fly or completely kept in FP8
- The optimizer states are almost always stored in FP32 or BF16, but some frameworks allow users to even quantize them to FP8
- For distributed training, the weights may be quantized to FP8 before collective ops like all-gather to cut communication cost
FP8-LM 7 from Microsoft explores multiple different ways FP8 can be integrated during training
- They use FP8 for storing gradient values
- They use an adaptive scaling ($\mu$) factor for gradients. This factor gets updated based on the proportion of gradient values underflowing or overflowing the range of FP8
- For distributed runs, they propose post-scaling of gradients where gradients from all ranks are first summed and then scaled per rank
- Master weights are stored in FP16 with per-tensor scaling and converted to FP8 for GEMM. From the paper:
-
It reveals that the master weight is precision-sensitive. This can be attributed to the master weight’s role in updating weights, which tend to exhibit small magnitudes, necessitating high precision to maintain accuracy
-
- Optimizer states are stored in FP8 (for magnitude) and FP16 (for direction). From the paper:
-
This stems from the fact that, during model updates in Adam, the direction of the gradient holds greater significance than its magnitude.
-
- Since FP8 parameters have a scale factor associated with them, the usual way of partitioning a tensor using NCCL primitives fails. They design novel ways of partitioning the FP8 tensor for distributed training
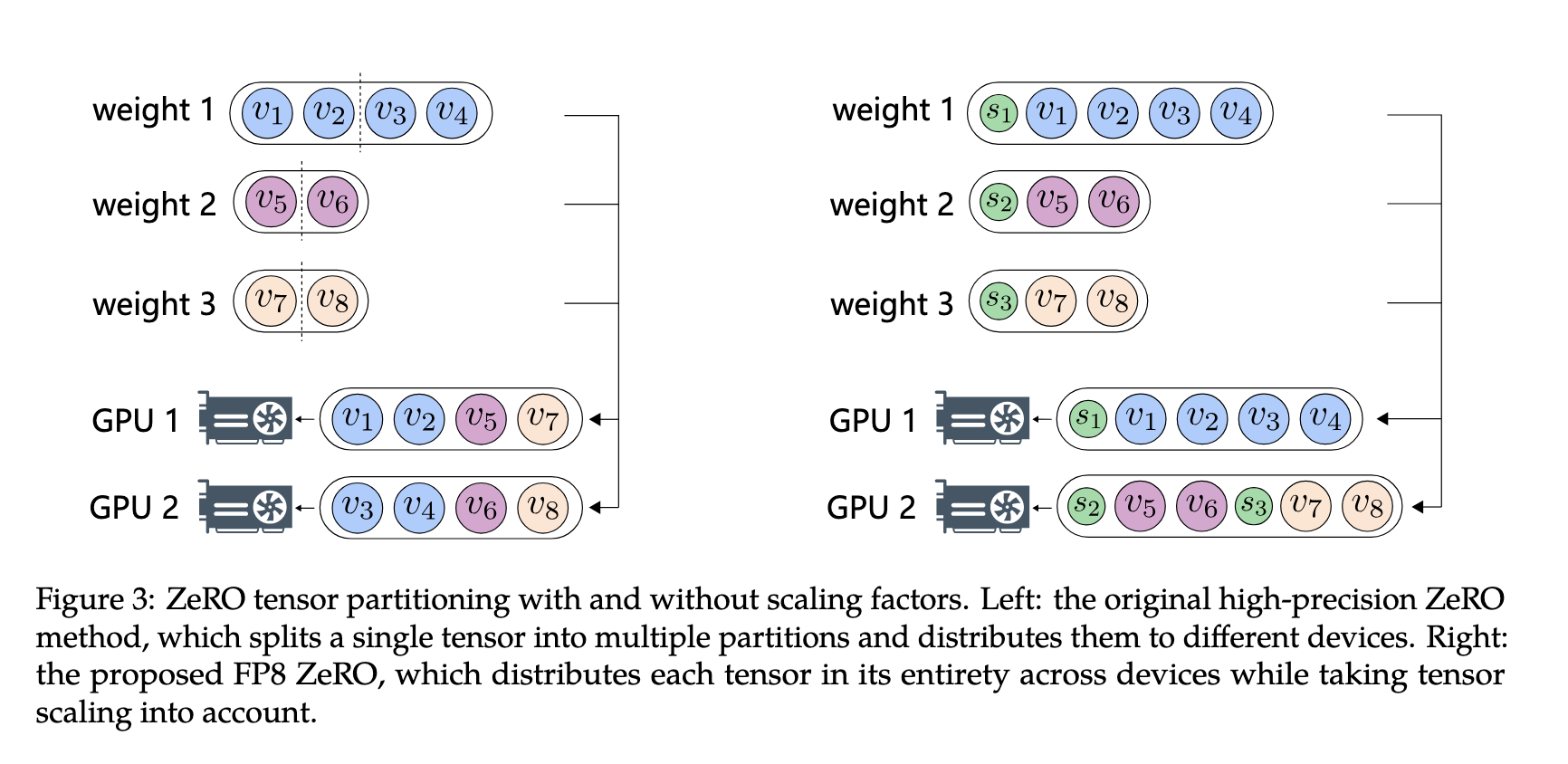
Deepseek introduced various innovations in using FP8 for training in their Deepseek V3 paper 8:
- GEMM uses FP8 input and BF16/FP32 accumulation and output (based on the depending op)
- Activations are stored in FP8 that are reused in the backward pass. This reduces the activation memory that can dominate memory usage in large sequence length
- Some layers (embedding, LM head, MoE routing layer, etc) still use BF16 GEMM
- AdamW optimizer uses BF16 for both magnitude and direction, master weights are stored in FP32, and gradients are also stored in FP32
- Block-wise scaling of weights (128x128) and activations (1x128). Since Deepseek V3 was trained on Hopper chips, they had to implement scaling manually. However, with Blackwell GPUs, block scaling can be handled natively
- GEMM accumulation is done in FP32 on CUDA cores, not Tensor Cores
- Online scaling instead of delayed scaling
- Activations before MoE up-projections are quantized to FP8 and then used for distributing across rank
| FP32 | Mixed precision | BF16 | FP8 LM | Deepseek v3 | |
|---|---|---|---|---|---|
| Weights | 4M | 2M+4M (FP32) | 2M | M+2M(FP16) | M+4M(FP32) |
| Gradients | 4M | 2M | 2M | M | 4M |
| Optimizer states | 4M+4M | 4M+4M (FP32) | 4M+4M | M+2M | 2M+2M |
| Total | 16M | 16M | 12M | 7M | 13M |
| Activation | A | A/2 | A/2 | A/4 | A/4 |
| Reduction | 1x | 1x | 0.75x | 0.43x | 0.81x |
Table: The above table compares FP32 training, mixed precision training, native BF16 training, FP8 LM 7, and Deepseek V3 8, considering a model with M parameters. The values are in bytes, expressed in terms of model parameters. The above is the ~peak memory usage during training. The table (incorrectly) assumes all operations in FP8, which is usually not the case.
Recipes for Pre-training LLMs with MXFP89 provides yet another alternative on using MX formats.
- It proposes to use the MXFP8-E4M3 format for all GEMM operations on Blackwell GPUs and does ablation studies proving the stability of training runs
- They also propose a strategy to quantize (specifically, round to nearest) to FP8 from higher precision
- Since the scaling is handled by the hardware, and is much more fine-grained (1x32 vs 1x128 used in Deepseek), MXFP8 results in better throughput and accuracy than just FP8+manual scaling
- Attention operations, Softmax, embedding layer, and the final output projection layer still use higher precision (BF16).
In most implementations, FP8 GEMMs are used in FFN and some projection layers, but not in attention. Towards Fully FP8 GEMM LLM Training at Scale 10 applies tweaks to the standard transformer architecture that enable applying FP8 GEMM to all the matmuls in the network. Why Low-Precision Transformer Training Fails 11 goes into much more detail about why lower precision attention computations can be risky.
Ant group goes a step further in their Zhihu post and designs their own fused kernels for FP8 reporting >50% gains in training throughput.
Performance gains
What are the performance gains that we get from opting FP8 for training? As we have seen that there are multiple different ways of infusing FP8 in training and hence there’s no one number or recipe that we can expect to target. However, various experimental results from Nvidia12 and PyTorch13 has shown somewhere between 1.3x to 1.5x improvement in training throughput on both Hopper and Blackwell chips. The speedups are larger for larger models. A few knobs that needs to be taken into consideration for improving performance while keep the accuracy degradation to a minimal:
- Choice of target layers: Start with targeting on FFN layers
- Choice of scaling: If Blackwell GPUs are available, opt for micro-scaling formats, otherwise start with row-wise current scaling since that is shown to have better training stability14
- Choice of precision of master weights, optimizer states and gradients
Quantization aware training (QAT)
In QAT, we emulate quantization during training. This is helpful in cases where we want to quantize the model after the training is completed. Usually, in QAT, the actual matmuls happen in BF16. The training is setup such that the model learns to handle quantization post training which leads to minimal performance degradation. From an efficiency perspective, we don’t see any benefits in training, so I will ignore this topic for the purpose of this blog.
This blog from PyTorch covers QAT in detail.
Inference
During inference, FP8 integration is simpler. FP8 consumes lesser memory and helps in memory bound operations. For example, a 24B model will take ~48G in BF16, but ~24G in FP8. This would result in having more memory for the KV cache and speedups in model weight transfer from HBM to cache.
If the model weights are already quantized (for example: GPT-OSS 15 which is released in MXFP4 format), popular serving frameworks like vLLM or SGLang can serve the models directly without any additional steps. This enables better throughput during the decoding stage, and on newer generation GPUs, GEMMs also take advantage of the native lower precision format support like FP8 and MXFP8. On older generation GPUs, the memory transfer savings remain. However, since they cannot perform native FP8/MXFP8 GEMMs, the weights must be upcasted to BF16 or FP16, which introduces some overhead. End-to-end gains are realized only when this casting overhead is smaller than the bandwidth savings from reduced memory transfer.
Post training quantization (PTQ) takes a trained model (e.g, in BF16) and converts it to FP8 for inference. The following sections covers two approaches to PTQ
Dynamic Post training quantization
The most straightforward way to convert a higher precision model to FP8 is to use a library like llm-compressor, which offers an option to convert BF16 checkpoints to FP8. The process includes calculating the scales of the weight tensors and storing it in the state dict. These scales can be per-tensor or blockwise, similar to what we saw in training.
However, FP8 GEMM still requires activations to be converted to FP8. Activations are quantized to FP8 on the fly. This usually degrades the performance gains one can expect from FP8 inference due to scale calculation of activations before performing GEMM. Since the activations are being quantized on the fly, this process is dynamic PTQ.
Static Post training quantization
Another apporach of converting a higher precision model to FP8 is as follows:
- Quantizing weights: Quantization of weights is similar to dynamic PTQ, where weight tensors are converted to FP8, and the calculated scales are stored in the state dict along with the corresponding FP8 weights.
- Calibration: Run a small, representative dataset through the original, high-precision model. During this step, the dynamic range (i.e., the minimum and maximum absolute values) of the activations is recorded.
- Scale Calculation: Compute a fixed, static scaling factor for each tensor (per-tensor or blockwise) based on those ranges. These scales (called as activation scales) are stored in the state dict along with the model weights.
During inference, both the weights and the corresponding scales are loaded to perform FP8 GEMMs. The scales for activations are also loaded and applied to the activation tensors on the fly. Static PTQ does not require scale calculation for activations before GEMM. That is why, it is usually faster (but less accurate) than Dynamic PTQ.
The choice of calibration dataset during PTQ is of high importance. See Section 4.1 of the Sarvam-M release blog for more information
Conclusion
FP8 for inference is usually straight-forward and easy to implement. It also leads to very minimal accuracy degradation (16, 17) and it’s already popular in leading inference providers.
But why the heck is FP8 not popular in training workloads? Based on what I have read, my opinion is that we are in the very early phases of using FP8 for training. If I were to make an analogy, we are in the days of using mixed precision recipes of FP16+FP32. With the evolution of hardware, we slowly moved to native BF16 training. Similarly, with hardware advancements (eg: native support for micro scaling formats in Blackwell GPUs), software tricks (9, 4) and architectural tweaks 10, we will move towards truly native FP8 training where 95%+ of the training time is spent in FP8.
Footnotes
References
These are some good follow up references to this blog for applications of FP8
- Lecture 30: Quantized Training
- Unified FP8: Moving Beyond Mixed Precision for Stable and Accelerated MoE RL
-
Floating-Point 8: An Introduction to Efficient, Lower-Precision AI Training ↩ ↩2
-
Why Low Precision Transformer Training Fails: An Analysis On Flash Attention ↩
-
Faster Training Throughput in FP8 Precision with NVIDIA NeMo ↩
-
“Give Me BF16 or Give Me Death”? Accuracy-Performance Trade-Offs in LLM Quantization ↩