The curious case of weight tying in LoRA
One fine day, I woke up and decided to write a training loop from scratch! JK. I had a project which involved lots of customization during the training loop. So I decided to write my own trainer loop instead of using TRL or transformers trainer. Writing a training loop is pretty straightforward. Until you start adding desires. You start craving higher batch sizes, distributed training and efficient methods to manage large models. Since I am a mortal, I too had the same desires.
I started adding complexity to my training loop bit by bit, and almost all of those complexities came with their own baggage of bugs and unsaid features. This is one of them.
PEFT
I wanted to use PEFT library to apply LoRA adapters to my model. However, for my specific use case, I had to extend the vocabulary of the model, which meant adding new embeddings corresponding to the new tokens in the embedding layer. These new embeddings are randomly initialized. To learn these embeddings during LoRA fine-tuning of the model, we have to either
- (More common) Add the embedding layer in
modules_to_saveargument of LoraConfig. This sets the complete layer as trainable. More concretely, it adds a wrapper class on the layer that encapsulates the original layer. - (Less common) Add the embedding layer in
target_modulesargument of LoraConfig. This adds a LoRA adapter to the embedding layer and these adapters are set as trainable. The base embedding layer (along with the new tokens in the vocabulary) are left untouched during PEFT tuning.
Weight tying
However, if we are working with a model which has its weight tied, then both of the proposed solutions run into issues. Weight tying ties the embedding layer (input embedding layer) to the language modeling head (output embedding layer). This means that both of these layers share the weights (and should share the updates during training). This reduces the model size and given that both of these layers are responsible for similar things (converting tokens to embeddings), just in reverse order, a lot of models opt for weight tying (including Gemma, Granite, Llama, Qwen family of models).
Let’s inspect the actual issue through code during PEFT tuning. First, let’s setup our environment:
python -m venv .peft
source .peft/bin/activate
# Install from main for the latest changes to reflect
pip install git+https://github.com/huggingface/peft.git
# I have not verified this behaviour in transformers v5 yet
pip install transformers==4.55.4
The complete code is here:
Essentially, I am doing the following:
- Loading a model that has tied weights
- Adding LoRA adapters and trainable modules to the model
- Training the model with some dummy data
- Post training, saving the model to a directory
- Loading the saved model
- Merging the adapters
- In (
modules_to_save) wrapper tuning, the complete layer is set as trainable, so the merging just results in the wrapper class being replaced by the trained layer - In (
target_modules) LoRA tuning, only the adapters are trained, so we have an option to merge the adapters with the base model
- In (
Between all of these steps, I am printing the mean of the tied layers and comparing them. This is the function that does it.
def print_means(m, adapter_name):
"""
Utility function to print and compare the means of the
input/output embedding layers
"""
emb = m.get_input_embeddings()
lm = m.get_output_embeddings()
print(f"Embedding layer mean: {emb.weight.mean().item():.2e}")
print(f"LM Head layer mean: {lm.weight.mean().item():.2e}")
# Indicates if the embedding layer was added in `modules_to_save`
if hasattr(emb, "modules_to_save"):
print(f"Embedding layer module wrapper mean: {emb.modules_to_save[adapter_name].weight.mean().item():.2e}")
if hasattr(lm, "modules_to_save"):
print(f"LM Head layer module wrapper mean: {lm.modules_to_save[adapter_name].weight.mean().item():.2e}")
try:
assert torch.allclose(emb.weight, lm.weight), "Embedding and LM layer are not equal"
assert emb.weight.data_ptr() == lm.weight.data_ptr(), (
"Embedding and LM layer do not have the same memory address"
)
print("✅ Embedding and LM layer are equal")
except Exception as err:
print(f"❌ {err}")
Modules to save
The model used above has weight tying enabled, which means its two layers model.embed_tokens and lm_head share the parameters.
Scenario 1: embed_tokens in modules_to_save
Let’s add embed_tokens in modules_to_save. If we run the above script (Command: python lora_modules_to_save.py --modules_to_save embed_tokens 1), only the embed_tokens will receive updates during the PEFT tuning. We are effectively breaking the weight tying, since lm_head is not receiving any updates during the training. After the training is completed, the two tied layers will have completely diverged. What’s fascinating is that the model config is not updated. So any downstream usage of this model directly with the huggingface ecosystem is risky!.
Here is the output after loading the model and adding training modules to the model.
Step 1: Loading a model with tied weights
Is weight tying enabled?: True
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
✅ Embedding and LM layer are equal
Step 2: Adding LoRA adapters and trainable modules to the model
trainable params: 2,064,512 || all params: 4,163,272 || trainable%: 49.5887
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
Embedding layer module wrapper mean: -1.74e-05
❌ Embedding and LM layer do not have the same memory address
Here is the output after tuning the model.
Step 3: Training the model with some dummy data
training: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 24.64it/s]
Step 4: Post training, saving the model to a directory
# Both the layers have diverged
Embedding layer mean: -1.73e-05
LM Head layer mean: -1.74e-05
Embedding layer module wrapper mean: -1.73e-05
❌ Embedding and LM layer are not equal
Saved the model to tmp
If we now reload the model and merge it, we would have completely destroyed weight tying.
Step 5: Loading the saved model
Is weight tying enabled?: True
Embedding layer mean: -1.73e-05
LM Head layer mean: -1.74e-05
Embedding layer module wrapper mean: -1.73e-05
❌ Embedding and LM layer are not equal
Step 6: Merging the adapters
Embedding layer mean: -1.73e-05
LM Head layer mean: -1.74e-05
❌ Embedding and LM layer are not equal
Done
A simple workaround is that we load the model in an untied manner and tie the weights manually. But that is not the correct way, because the lm_head layer was not actually updated during training.
Scenario 2: embed_tokens and lm_head in modules_to_save
If we run the same script as above (just with modules_to_save == ["embed_tokens", "lm_head"]), would we solve the issue? Let’s try (Command: python lora_modules_to_save.py --modules_to_save embed_tokens lm_head 1)
Step 1: Loading a model with tied weights
Is weight tying enabled?: True
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
✅ Embedding and LM layer are equal
Step 2: Adding LoRA adapters and trainable modules to the model
trainable params: 4,112,512 || all params: 6,211,272 || trainable%: 66.2105
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
Embedding layer module wrapper mean: -1.74e-05
LM Head layer module wrapper mean: -1.74e-05
❌ Embedding and LM layer do not have the same memory address
Step 3: Training the model with some dummy data
training: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 28.58it/s]
Step 4: Post training, saving the model to a directory
# Again, both the layers have completely diverged during training
Embedding layer mean: -1.73e-05
LM Head layer mean: 1.11e-03
Embedding layer module wrapper mean: -1.73e-05
LM Head layer module wrapper mean: 1.11e-03
❌ Embedding and LM layer are not equal
Saved the model to tmp
Step 5: Loading the saved model
Is weight tying enabled?: True
Embedding layer mean: -1.73e-05
LM Head layer mean: 1.11e-03
Embedding layer module wrapper mean: -1.73e-05
LM Head layer module wrapper mean: 1.11e-03
❌ Embedding and LM layer are not equal
Step 6: Merging the adapters
Embedding layer mean: -1.73e-05
LM Head layer mean: 1.11e-03
❌ Embedding and LM layer are not equal
Done
Even when both layers are set as trainable, the weights of the layers have diverged during training. This is because PEFT adds a wrapper object on all the layers passed through modules_to_save. This wrapper creates a new object which wraps the original layer effectively untying the layers. All the tied layers receive separate updates during training. This breaks what one might expect from PEFT tuning.
Target modules
What if we instead add tied layers in target_modules? When we add a layer to target_modules, PEFT adds LoRA adapters to them. Unlike modules_to_save, only these adapters (A and B) are updated during tuning instead of the complete layer. This time, we will track the changes in the Lora adapters (A and B) of the targetted layers too (called as delta weights lora_A@lora_B). The code is very similar to the above gist, with a couple of changes. The complete code is referenced below 2.
Scenario 1: embed_tokens and lm_head in target_modules
First, I have updated the print_means method to compare the changes in Lora adapters too.
def print_means(m, adapter_name):
"""
Utility function to print and compare the means of the
input/output embedding layers
"""
emb = m.get_input_embeddings()
lm = m.get_output_embeddings()
print(f"Embedding layer mean: {emb.weight.mean().item():.2e}")
print(f"LM Head layer mean: {lm.weight.mean().item():.2e}")
# Indicates if the embedding layer has LoRA adapters added
if isinstance(emb, LoraLayer):
print(f"Embedding layer Lora A adapter mean: {emb.lora_embedding_A[adapter_name].mean().item():.2e}")
print(f"Embedding layer Lora B adapter mean: {emb.lora_embedding_B[adapter_name].mean().item():.2e}")
if isinstance(lm, LoraLayer):
print(f"LM head Lora A adapter mean: {lm.lora_A[adapter_name].weight.mean().item():.2e}") # type: ignore
print(f"LM head Lora B adapter mean: {lm.lora_B[adapter_name].weight.mean().item():.2e}") # type: ignore
try:
assert torch.allclose(emb.weight, lm.weight), "Embedding and LM layer are not equal"
assert emb.weight.data_ptr() == lm.weight.data_ptr(), (
"Embedding and LM layer do not have the same memory address"
)
print("✅ Embedding and LM layer are equal")
except Exception as err:
print(f"❌ {err}")
# Compare delta weights
e_eff = emb.weight
lm_eff = lm.weight
if isinstance(emb, LoraLayer):
e_eff = e_eff + emb.get_delta_weight(adapter_name) # type: ignore
if isinstance(lm, LoraLayer):
lm_eff = lm_eff + lm.get_delta_weight(adapter_name) # type: ignore
try:
assert torch.allclose(e_eff, lm_eff, atol=1e-5), (
"Embedding and LM layer effective weights are are not equal"
)
print("✅ Effective weights from lora adapters are same for Embedding and the LM layer")
except Exception as err:
print(f"❌ {err}")
Second, I have updated the LoraConfig that we provide to the model. This time, I have added Lora adapters to both tied layers, embed_tokens and lm_head
lora_cfg = LoraConfig(
target_modules=["embed_tokens", "lm_head"],
task_type="CAUSAL_LM"
)
If we apply the above LoraConfig and see the output, we see the similar behaviour to what we saw earlier. Separate Lora adapters are added to embed_tokens and lm_head. If we merge the model after tuning (or use it as is), the embed_tokens and lm_head have effectively diverged. The effective op (which combines the base weight + LoRA adapters) from both the layers will be different. (Command: python lora_target_modules.py --target_modules embed_tokens lm_head 2)
Step 1: Loading a model with tied weights
Is weight tying enabled?: True
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
✅ Embedding and LM layer are equal
✅ Effective weights from lora adapters are same for Embedding and the LM layer
Step 2: Adding LoRA adapters and trainable modules to the model
trainable params: 4,096,128 || all params: 6,194,888 || trainable%: 66.1211
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
Embedding layer Lora A adapter mean: 0.00e+00
Embedding layer Lora B adapter mean: 8.47e-02
LM head Lora A adapter mean: -1.43e-02
LM head Lora B adapter mean: 0.00e+00
✅ Embedding and LM layer are equal
# Even though lora adapter means are different, effective op is same because one of the adapters is all zeros
✅ Effective weights from lora adapters are same for Embedding and the LM layer
Step 3: Training the model with some dummy data
training: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 35.17it/s]
Step 4: Post training, saving the model to a directory
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
Embedding layer Lora A adapter mean: -4.39e-07
Embedding layer Lora B adapter mean: 8.44e-02
LM head Lora A adapter mean: -1.43e-02
LM head Lora B adapter mean: -9.41e-04
# The base layer is still the same
✅ Embedding and LM layer are equal
# Since the adapter weights have diverged, the effective operation of W + W_delta diverges for both tied layers
# W_delta is A@B
❌ Embedding and LM layer effective weights are are not equal
Saved the model to tmp
embed_tokensandlm_headLoRA adapters are transposed views of each other. Embedding LoRA A = lm head LoRA B (similarly for the other adapter). This is a special case since LoRa adapters applied to the embedding layers is a bit different from linear layers.
Interestingly, if we merge the model, we would see that the tying is maintained, but internally during tuning, both layers saw different updates (verified in Step 4). So the effective merging yields incorrect weights for the tied layers.
Step 5: Loading the saved model
Is weight tying enabled?: True
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
Embedding layer Lora A adapter mean: -4.39e-07
Embedding layer Lora B adapter mean: 8.44e-02
LM head Lora A adapter mean: -1.43e-02
LM head Lora B adapter mean: -9.41e-04
✅ Embedding and LM layer are equal
❌ Embedding and LM layer effective weights are are not equal
Step 6: Merging the adapters
Embedding layer mean: 3.60e-04
LM Head layer mean: 3.60e-04
# Explaination below!
✅ Embedding and LM layer are equal
✅ Effective weights from lora adapters are same for Embedding and the LM layer
Done
The adapters are getting merged twice because PEFT walks the model in a linear order. It sees embed_tokens first and merges the adapter into it. Later, when it reaches lm_head, which is weight-tied to embed_tokens — it merges the adapter to the same underlying weight. Because both modules share the same tensor, the adapter deltas accumulate twice, inflating the final weights. Note that since the config of the model states that they are weight tied, the base weights are tied while loading the model. This does not happen in the case of modules_to_save since in that case, the base weights itself change.
Solution
Okay. So what’s the solution? I was definitely not the one who discovered this bug for the first time. A lot of people discovered it independently. After spending a frustrating amount of hours on this, I figured out how I could solve this and contributed (PR1 and PR2) a new flag ensure_weight_tying to PEFT, specifically for LoraConfig. Enabling this flag, solves the unexpected behaviour shared above.
Scenario 1: Modules to save
This is the output for modules_to_save = ["embed_tokens"] and ensure_weight_tying=True in LoraConfig.
Command: python lora_modules_to_save.py --modules_to_save embed_tokens --ensure_weight_tying 1
Step 1: Loading a model with tied weights
Is weight tying enabled?: True
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
✅ Embedding and LM layer are equal
Step 2: Adding LoRA adapters and trainable modules to the model
trainable params: 2,064,512 || all params: 4,163,272 || trainable%: 49.5887
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
Embedding layer module wrapper mean: -1.74e-05
# Note how LM head also has a module now
LM Head layer module wrapper mean: -1.74e-05
✅ Embedding and LM layer are equal
Step 3: Training the model with some dummy data
training: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 27.57it/s]
Step 4: Post training, saving the model to a directory
Embedding layer mean: 3.22e-04
LM Head layer mean: 3.22e-04
Embedding layer module wrapper mean: 3.22e-04
LM Head layer module wrapper mean: 3.22e-04
# YESSS.. both the tied layers have received exactly the same updates!
✅ Embedding and LM layer are equal
Saved the model to tmp
Step 5: Loading the saved model
Is weight tying enabled?: True
Embedding layer mean: 3.22e-04
LM Head layer mean: 3.22e-04
Embedding layer module wrapper mean: 3.22e-04
LM Head layer module wrapper mean: 3.22e-04
✅ Embedding and LM layer are equal
Step 6: Merging the adapters
Embedding layer mean: 3.22e-04
LM Head layer mean: 3.22e-04
✅ Embedding and LM layer are equal
Done
Scenario 2: Target modules
This is the output for target_modules = ["embed_tokens"] and ensure_weight_tying=True in LoraConfig.
Command: python lora_target_modules.py --target_modules embed_tokens --ensure_weight_tying 2
Step 1: Loading a model with tied weights
Is weight tying enabled?: True
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
✅ Embedding and LM layer are equal
✅ Effective weights from lora adapters are same for Embedding and the LM layer
Step 2: Adding LoRA adapters and trainable modules to the model
trainable params: 4,096,128 || all params: 6,194,888 || trainable%: 66.1211
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
Embedding layer Lora A adapter mean: 0.00e+00
Embedding layer Lora B adapter mean: -4.74e-02
LM head Lora A adapter mean: -4.74e-02
LM head Lora B adapter mean: 0.00e+00
✅ Embedding and LM layer are equal
✅ Effective weights from lora adapters are same for Embedding and the LM layer
Step 3: Training the model with some dummy data
training: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 44.29it/s]
Step 4: Post training, saving the model to a directory
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
Embedding layer Lora A adapter mean: 4.21e-04
Embedding layer Lora B adapter mean: -4.74e-02
LM head Lora A adapter mean: -4.74e-02
LM head Lora B adapter mean: 4.21e-04
# JOY!!
✅ Embedding and LM layer are equal
✅ Effective weights from lora adapters are same for Embedding and the LM layer
Saved the model to tmp
Step 5: Loading the saved model
Is weight tying enabled?: True
Embedding layer mean: -1.74e-05
LM Head layer mean: -1.74e-05
Embedding layer Lora A adapter mean: 4.21e-04
Embedding layer Lora B adapter mean: -4.74e-02
LM head Lora A adapter mean: -4.74e-02
LM head Lora B adapter mean: 4.21e-04
✅ Embedding and LM layer are equal
✅ Effective weights from lora adapters are same for Embedding and the LM layer
Step 6: Merging the adapters
Embedding layer mean: 2.06e-04
LM Head layer mean: 2.06e-04
✅ Embedding and LM layer are equal
✅ Effective weights from lora adapters are same for Embedding and the LM layer
Done
Conclusion
In both the above scenarios, as long as we have added one of the tied layers (it works when both are added too ^_^), ensure_weight_tying would enable parameter sharing for LoRA adapters as well as wrapper over tied layers. All the tied layers receive the same updates during training and the weight tying remains consistent after training.
Empirical evidence
To test whether this also affects real fine-tuning, I asked claude code to run a small experiment on Qwen2.5-0.5B with tatsu-lab/alpaca (5,000 train / 500 eval):
- Add new tokens to the embedding layer.
- Train with
embed_tokensinmodules_to_saveunder two settings:- (
fixed)ensure_weight_tying == True - (
broken)ensure_weight_tying == False
- (
- Train a baseline model with no added tokens.
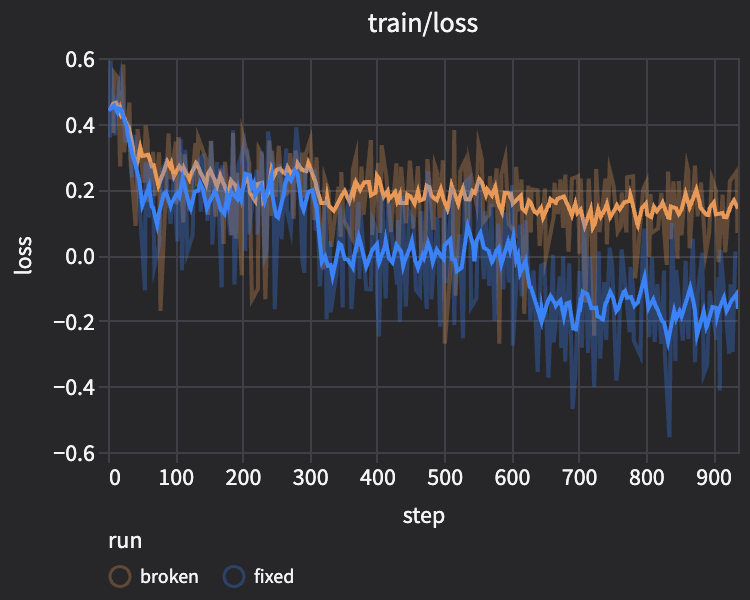
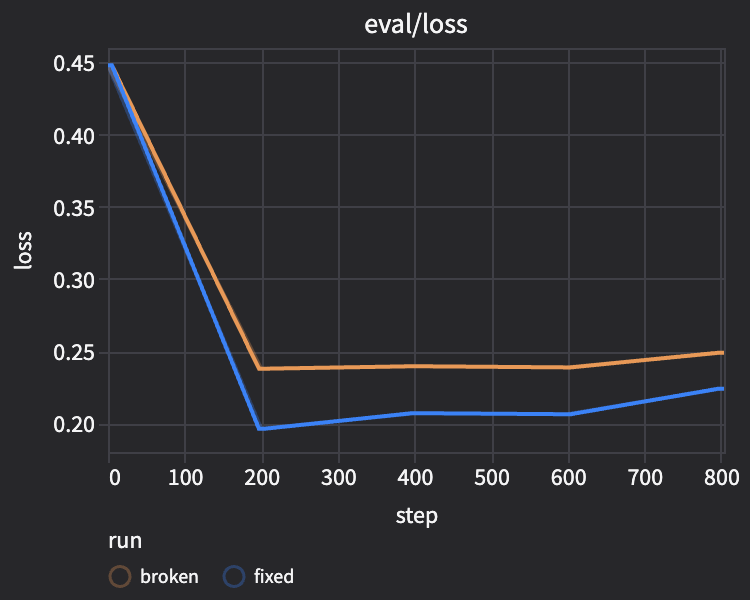
From the results, we see:
- Both train and eval loss are lower for the
fixedrun than thebrokenrun.
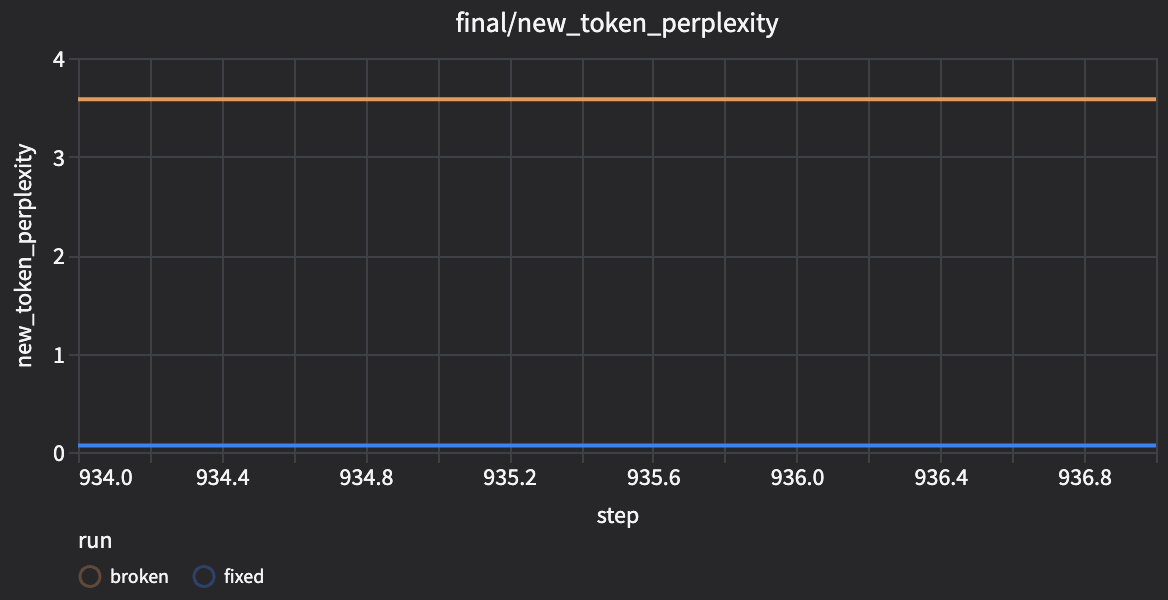
- New-token perplexity is much lower in the
fixedrun:1.16vs3810.89(~3274xlower).
- The
fixedmodel generates sequences with the new tokens much more reliably (49/50strict structural matches vs0/50forbroken).
These results support the ensure_weight_tying flag.
The complete code and additional analysis are in the GitHub repo, and the training metrics are on Trackio.
References
Here’s the gist for the code I used on this post:
Note: I have removed a few warning messages and loading TQDM from the output to keep it uncluttered.