..
CLIP
CLIP
The major reasons to build a model like CLIP:
- To improve general performance of visual models
- If a model is trained to predict on 10 classes, it wont work for a task where we have to predict 100 classes
- The output space also gets constricted for if we try to predict for pre-defined categories only
- Save the cost of building a labelled dataset
Understanding model input/output
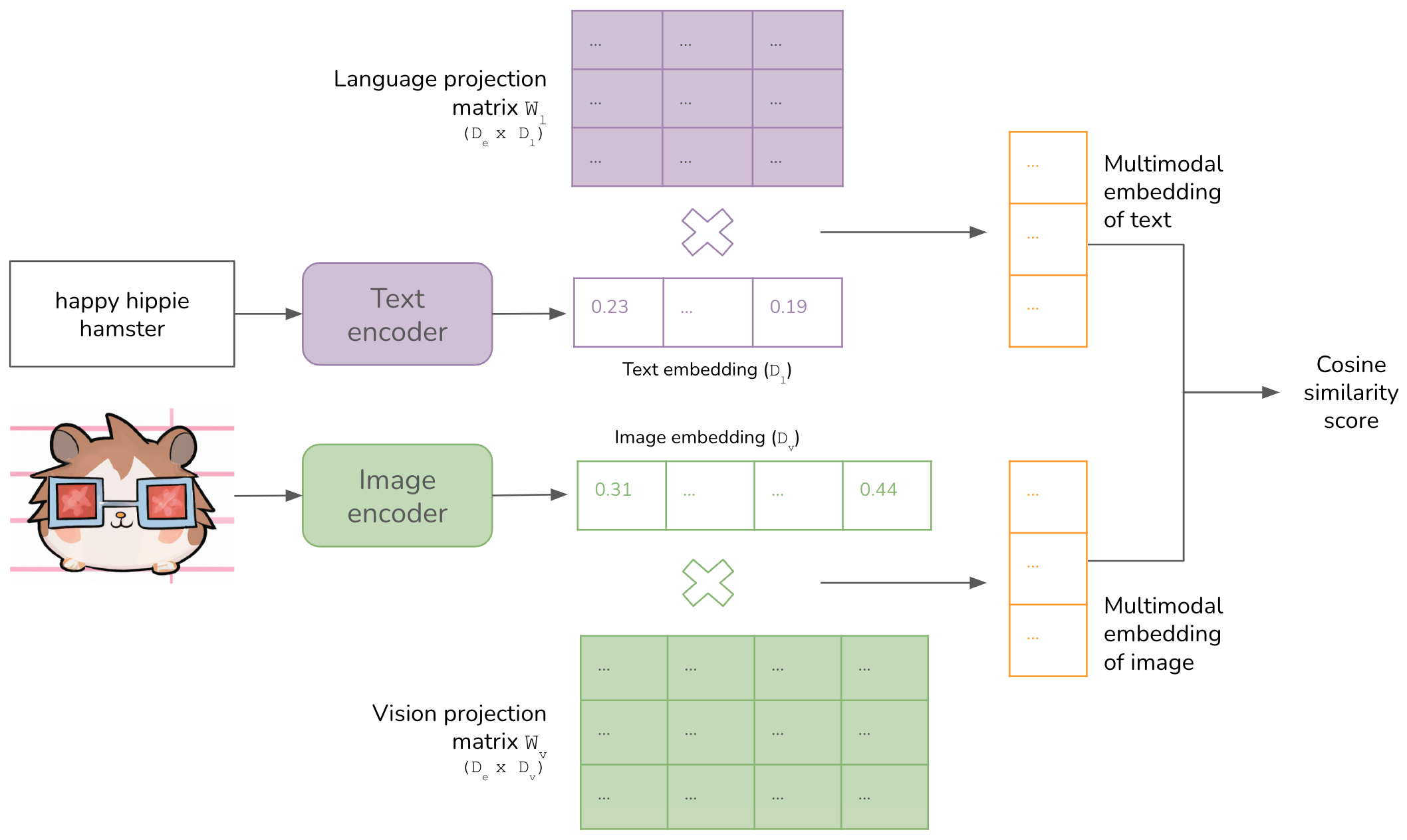
- The input of the model is an image
- Labels: The output of the model is randomly sampled text. These text are captions of the image, where one of the caption is the actual caption of the image. This text is also encoded and projected in the same space
- The model tries to predict, which of the captions actually describes the image in the best way - There is another way to model the same problem. We can generate text given an image. But the authors found that to do supervised training using this, it was tough for the model to generate the exact text captions provided - Instead of predicting the exact text of each image, CLIP was trained to predict whether a text is more likely to accompany an image than other texts
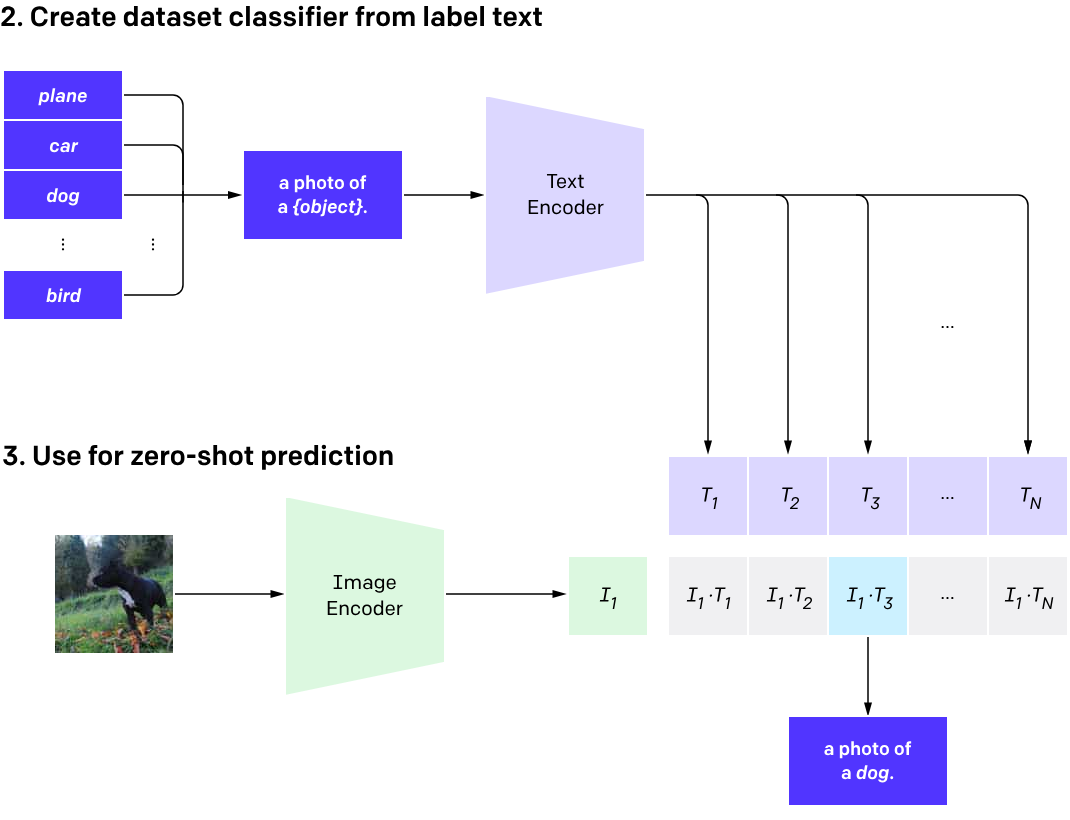
- To use it in a downstream binary classification problem, we can create the labels like: A photo of
<class1 or class2>and pass it to the text encoder
Implementation details
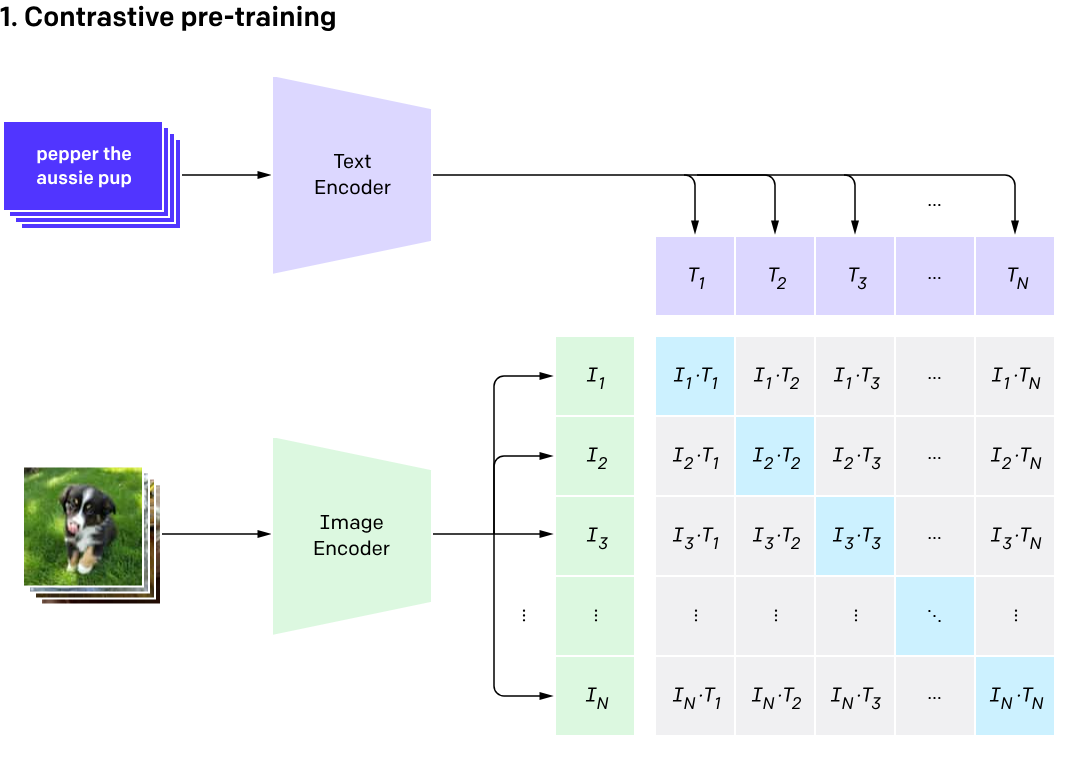
- CLIP uses Noise Contrastive Estimation.
- Contrastive Learning refers to the approach of learning representations by contrasting positive pairs against negative pairs. In the context of CLIP, positive pairs are the correctly matching image-text combinations, and negative pairs are the non-matching combinations. This method teaches the model to understand the content and semantics of both images and texts by focusing on the similarities and differences among them, effectively aligning the embedding spaces of the two modalities.
Applications
- DALL-E: Given a text prompt, DALL-E generates many different visuals. It then encodes each of these images using CLIP image encoder and encodes text prompt using CLIP text encoder. It then rerank the visuals before showing the top visuals to users.
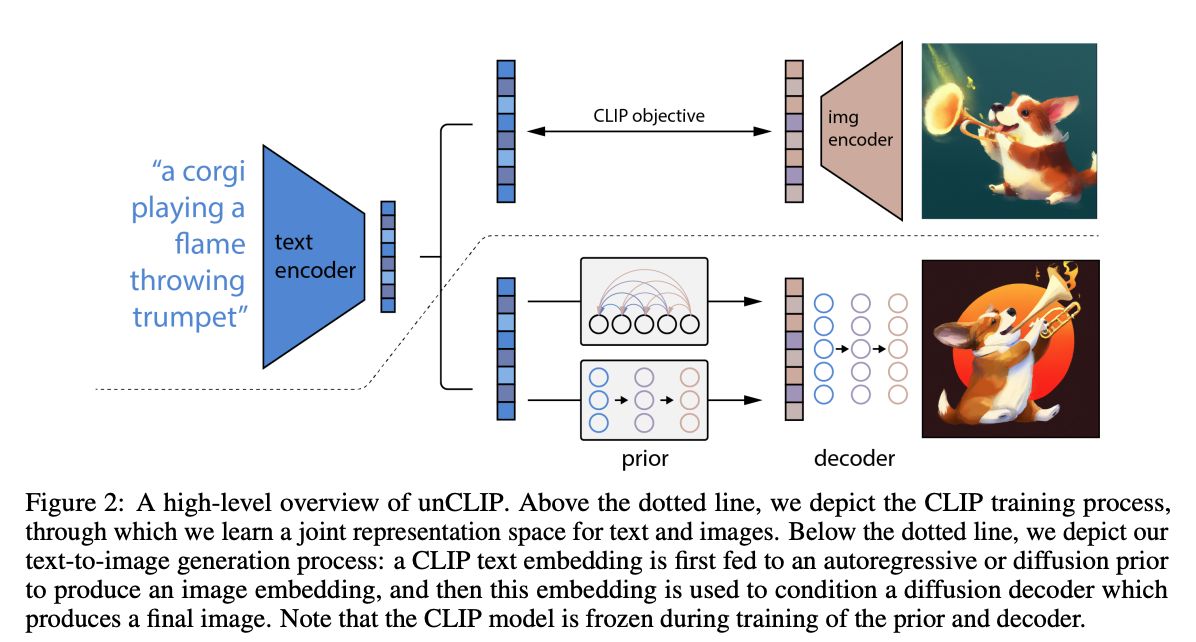
- unCLIP: Given a text prompt generate a text embedding using CLIP.
- During training
- The diffusion model will generate a image.
- Generate the embedding of the image using CLIP. The diffusion model uses both of these embedding to improve it’s model (image embedding is used as target, I think?)
- During inference CLIP encoder is used to encode the text and the diffusion model depends on this embedding to generate an image
- During training